この短いガイドでは、NumPy 配列を Pandas DataFrame に変換する方法を説明します。
手順は次のとおりです。
NumPy配列をPandas DataFrameに変換する手順
ステップ1: NumPy配列を作成する
たとえば、数値データ (つまり整数) のみを含む次の NumPy 配列を作成しましょう。
import numpy as np
my_array = np.array([[11, 22, 33], [44, 55, 66]])
print(my_array)
print(type(my_array))
Python でコードを実行すると、次の NumPy 配列が得られます。
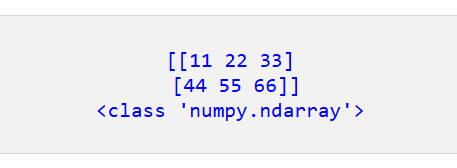
ステップ2: NumPy配列をPandas DataFrameに変換する
次の構文を使用して、NumPy 配列を Pandas DataFrame に変換できるようになりました。
import numpy as np
import pandas as pd
my_array = np.array([[11, 22, 33], [44, 55, 66]])
df = pd.DataFrame(my_array, columns=['Column_A', 'Column_B', 'Column_C'])
print(df)
print(type(df))
これで、3 つの列を持つ DataFrame が取得されます。
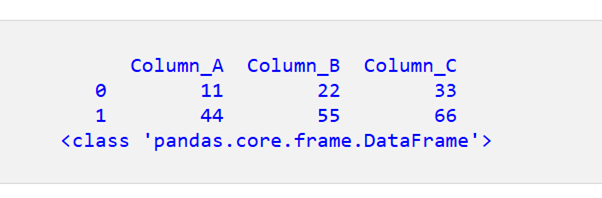
ステップ3(オプション):データフレームにインデックスを追加する
DataFrame にインデックスを追加したい場合はどうすればよいでしょうか?
たとえば、DataFrame に次のインデックスを追加してみましょう。
index=['Item_1', 'Item_2']
配列をインデックス付きの DataFrame に変換する完全なコードは次のとおりです。
import numpy as np
import pandas as pd
my_array = np.array([[11, 22, 33], [44, 55, 66]])
df = pd.DataFrame(my_array, columns=['Column_A', 'Column_B', 'Column_C'], index=['Item_1', 'Item_2'])
print(df)
print(type(df))
DataFrame の左側にインデックスが表示されます。
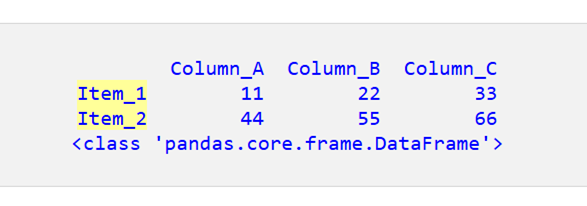
配列には文字列と数値データが混在しています
次に、文字列と数値データが混在する新しい NumPy 配列を作成しましょう (この配列の dtype はオブジェクトに設定されます)。
import numpy as np
my_array = np.array([['Jon', 25, 1995, 2016], ['Maria', 47, 1973, 2000], ['Bill', 38, 1982, 2005]], dtype=object)
print(my_array)
print(type(my_array))
print(my_array.dtype)
以下はオブジェクト dtype を持つ新しい配列です。
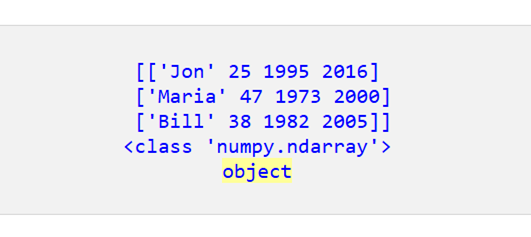
次に、次の構文を使用して、NumPy 配列を DataFrame に変換できます。
import numpy as np
import pandas as pd
my_array = np.array([['Jon', 25, 1995, 2016], ['Maria', 47, 1973, 2000], ['Bill', 38, 1982, 2005]], dtype=object)
df = pd.DataFrame(my_array, columns=['Name', 'Age', 'Birth Year', 'Graduation Year'])
print(df)
print(type(df))
新しい DataFrame は次のとおりです。
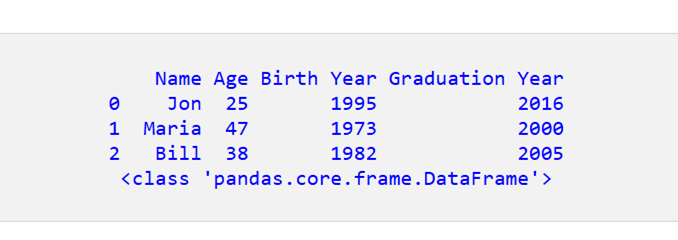
コードに df.dtypes を追加して、新しい DataFrame 内のすべての列のデータ型を確認しましょう。
import numpy as np
import pandas as pd
my_array = np.array([['Jon', 25, 1995, 2016], ['Maria', 47, 1973, 2000], ['Bill', 38, 1982, 2005]], dtype=object)
df = pd.DataFrame(my_array, columns=['Name', 'Age', 'Birth Year', 'Graduation Year'])
print(df)
print(type(df))
print(df.dtypes)
現在、DataFrame の下のすべての列はオブジェクト/文字列です。
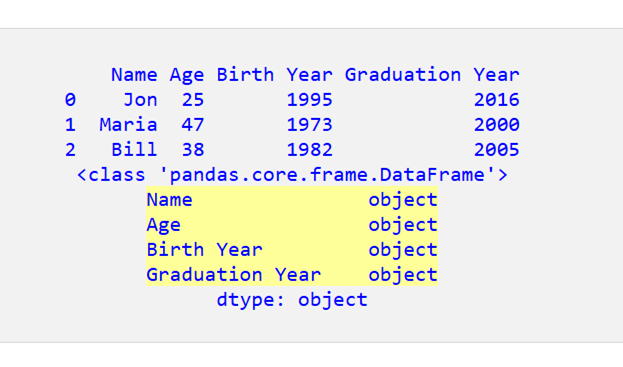
DataFrame 内の一部の列をオブジェクト/文字列から整数に変換したい場合はどうすればよいでしょうか?
たとえば、DataFrame の最後の 3 列を整数に変換したいとします。
この目的を達成するには、以下のように astype(int) を使用できます。
import numpy as np
import pandas as pd
my_array = np.array([['Jon', 25, 1995, 2016], ['Maria', 47, 1973, 2000], ['Bill', 38, 1982, 2005]], dtype=object)
df = pd.DataFrame(my_array, columns=['Name', 'Age', 'Birth Year', 'Graduation Year'])
df['Age'] = df['Age'].astype(int)
df['Birth Year'] = df['Birth Year'].astype(int)
df['Graduation Year'] = df['Graduation Year'].astype(int)
print(df)
print(type(df))
print(df.dtypes)
astype(int) を使用すると、これらの 3 つの列に対して int32 が提供されます。
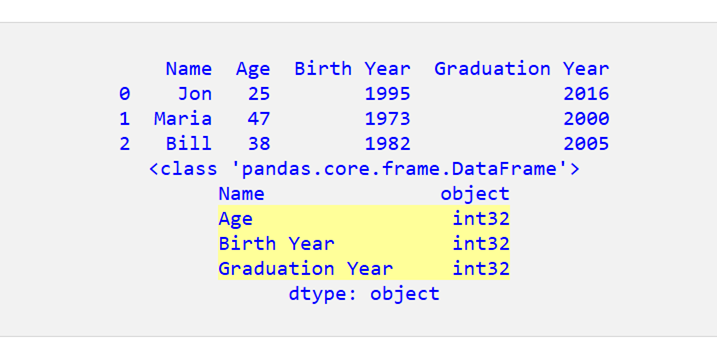
あるいは、apply(int) を使用すると、最後の 3 列に int64 が返されます。
import numpy as np
import pandas as pd
my_array = np.array([['Jon', 25, 1995, 2016], ['Maria', 47, 1973, 2000], ['Bill', 38, 1982, 2005]], dtype=object)
df = pd.DataFrame(my_array, columns=['Name', 'Age', 'Birth Year', 'Graduation Year'])
df['Age'] = df['Age'].apply(int)
df['Birth Year'] = df['Birth Year'].apply(int)
df['Graduation Year'] = df['Graduation Year'].apply(int)
print(df)
print(type(df))
print(df.dtypes)
ご覧のとおり、DataFrame の最後の 3 列は int64 になっています。
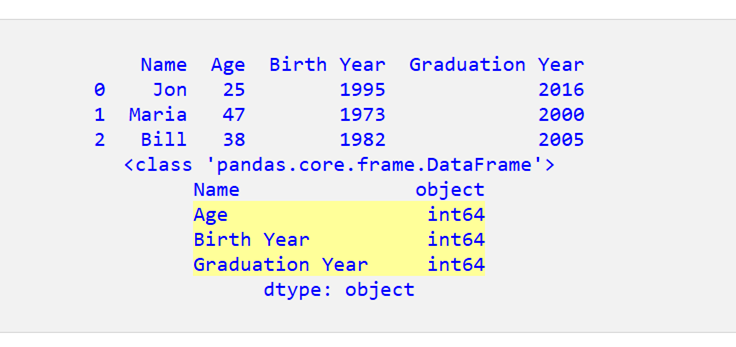





")