このアプローチを使用すると、Pandas DataFrame 内の重複をカウントできます。
df.pivot_table(columns=['DataFrame Column'], aggfunc='size')この短いガイドでは、Pandas DataFrame で重複をカウントする 3 つのケースを紹介します。
- 1列の下
- 複数の列にまたがって
- DataFrameにNaN値がある場合
Pandas DataFrame で重複をカウントする 3 つのケース
ケース1: 単一のDataFrame列の重複を数える
次のようなデータがある簡単なケースから始めましょう。
| Color | Shape |
| Green | Rectangle |
| Green | Rectangle |
| Green | Square |
| Blue | Rectangle |
| Blue | Square |
| Red | Square |
| Red | Square |
| Red | Rectangle |
Pandas DataFrameを使用してPythonで上記のデータを取得できます。
import pandas as pd
data = {'Color': ['Green', 'Green', 'Green', 'Blue', 'Blue', 'Red', 'Red', 'Red'],
'Shape': ['Rectangle', 'Rectangle', 'Square', 'Rectangle', 'Square', 'Square', 'Square', 'Rectangle']
}
df = pd.DataFrame(data)
print(df)
すると次の DataFrame が取得されます:

色と形状の両方の列に重複が見られます。
次に、このガイドの冒頭で紹介した方法を使用して、各列の重複をカウントできます。
df.pivot_table(columns=['DataFrame Column'], aggfunc='size')Pandasシリーズをデータフレームに変換する手順
ステップ1: シリーズを作成する
簡単な例から始めるために、5 つの項目のリストから Pandas シリーズを作成しましょう。
import pandas as pd
data = {'Color': ['Green', 'Green', 'Green', 'Blue', 'Blue', 'Red', 'Red', 'Red'],
'Shape': ['Rectangle', 'Rectangle', 'Square', 'Rectangle', 'Square', 'Square', 'Square', 'Rectangle']
}
df = pd.DataFrame(data)
duplicates_color = df.pivot_table(columns=['Color'], aggfunc='size')
print(duplicates_color)
そしてこれが結果です:

あるいは、次のコードを使用して Shape 列の重複の数を取得することもできます。
import pandas as pd
data = {'Color': ['Green', 'Green', 'Green', 'Blue', 'Blue', 'Red', 'Red', 'Red'],
'Shape': ['Rectangle', 'Rectangle', 'Square', 'Rectangle', 'Square', 'Square', 'Square', 'Rectangle']
}
df = pd.DataFrame(data)
duplicates_shape = df.pivot_table(columns=['Shape'], aggfunc='size')
print(duplicates_shape)
すると、各図形に対して 4 つの重複が作成されます。
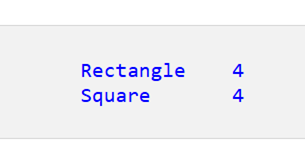
ケース2: 複数の列にわたる重複を数える
複数の列にわたって重複をカウントしたい場合はどうすればよいでしょうか?
たとえば、「color」列と「shape」列の両方で重複をカウントしたい場合はどうすればよいでしょうか。
その場合は、次のように必要なすべての列を追加するだけです。
columns=['Color', 'Shape']したがって、完全な Python コードは次のようになります。
import pandas as pd
data = {'Color': ['Green', 'Green', 'Green', 'Blue', 'Blue', 'Red', 'Red', 'Red'],
'Shape': ['Rectangle', 'Rectangle', 'Square', 'Rectangle', 'Square', 'Square', 'Square', 'Rectangle']
}
df = pd.DataFrame(data)
duplicates_color_and_shape = df.pivot_table(columns=['Color', 'Shape'], aggfunc='size')
print(duplicates_color_and_shape)
コードを実行すると、Color 列と Shape 列の両方で重複の数を取得できます。

ケース3: DataFrameにNaN値がある場合に重複を数える
3 番目のケースでは、NaN 値を含む次のデータセットを使用します。
| values |
| 700 |
| NaN |
| 700 |
| NaN |
| 800 |
| 700 |
| 800 |
NaN 値を含む DataFrame は次のようになります。
import pandas as pd
import numpy as np
df = pd.DataFrame({'values': [700, np.nan, 700, np.nan, 800, 700, 800]})
print(df)
コードを実行すると、次の NaN 値が表示されます。

次に、同じアプローチを適用して重複をカウントできます。
import pandas as pd
import numpy as np
df = pd.DataFrame({'values': [700, np.nan, 700, np.nan, 800, 700, 800]})
duplicates_values = df.pivot_table(columns=['values'], aggfunc='size')
print(duplicates_values)
結果は次のとおりです。

NaN 値のカウントも取得するには、それらの NaN 値を任意の値に置き換えてからカウントを実行します。
たとえば、fillna を使用して NAN 値を ‘NULL’ の式に置き換えてみましょう。
import pandas as pd
import numpy as np
df = pd.DataFrame({'values': [700, np.nan, 700, np.nan, 800, 700, 800]})
df['values'] = df['values'].fillna('NULL')
duplicates_values = df.pivot_table(columns=['values'], aggfunc='size')
print(duplicates_values)
すると、NULL エントリのカウントが 2 になります。これは実際には 2 つの NaN 値を表します。






