DataFrame 内の特定の列の記述統計を取得するには:
df["dataframe_column"].describe()DataFrame 全体の記述統計を取得するには:
df.describe(include="all")手順
ステップ1: データを収集する
まず、DataFrame のデータを収集します。
データセットの例を次に示します。
| product | price | year |
| A | 22000 | 2014 |
| B | 27000 | 2015 |
| C | 25000 | 2016 |
| C | 29000 | 2017 |
| D | 35000 | 2018 |
ステップ2: データフレームを作成する
次に、収集したデータに基づいて DataFrame を作成します。
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
print(df)
Python でコードを実行すると、次の DataFrame が得られます。
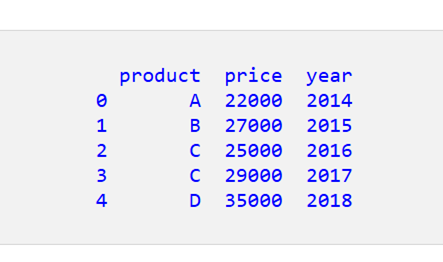
ステップ3:記述統計を取得する
数値データを含む「価格」列の記述統計を取得するには、次のようにします。
df["price"].describe()完全なコード:
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
stats_numeric = df["price"].describe()
print(stats_numeric)
「price」列の記述統計の結果:
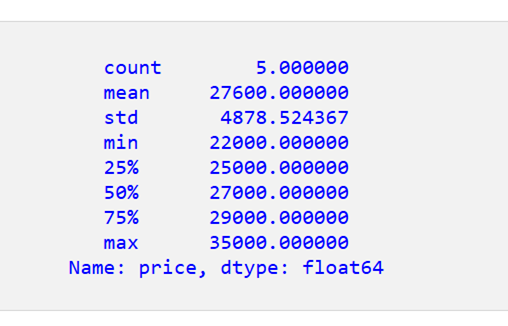
出力には小数点以下6桁が含まれていることに注意してください。astype(int)を使用して値を整数に変換できます。
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
stats_numeric = df["price"].describe().astype(int)
print(stats_numeric)
コードを実行すると、整数のみが取得されます。
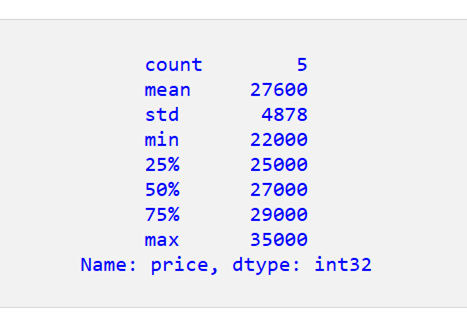
カテゴリデータの記述統計
カテゴリデータを含む「product」列の記述統計を取得するには:
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
stats_categorical = df["product"].describe()
print(stats_categorical)
結果は次のとおりです。
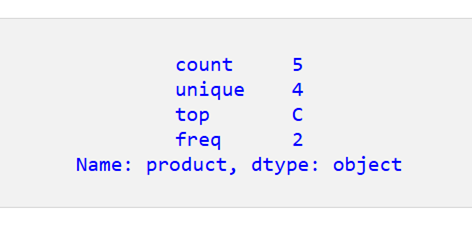
データフレーム全体の記述統計を取得する
DataFrame 全体の記述統計を取得するには:
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
stats = df.describe(include="all")
print(stats)
結果:

記述統計の分析
記述統計は次のようにさらに細分化できます。
カウント:
df["dataframe_column"].count()平均:
df["dataframe_column"].mean()標準偏差:
df["dataframe_column"].std()最小:
df["dataframe_column"].min()0.25 四分位数:
df["dataframe_column"].quantile(q=0.25)0.50 分位値(中央値):
df["dataframe_column"].quantile(q=0.50)0.75 四分位数:
df["dataframe_column"].quantile(q=0.75)最大:
df["dataframe_column"].max()すべてをまとめると:
import pandas as pd
data = {
"product": ["A", "B", "C", "C", "D"],
"price": [22000, 27000, 25000, 29000, 35000],
"year": [2014, 2015, 2016, 2017, 2018],
}
df = pd.DataFrame(data)
statistics = {
"count": df["price"].count(),
"mean": df["price"].mean(),
"std": df["price"].std(),
"min": df["price"].min(),
"quantile_25": df["price"].quantile(q=0.25),
"quantile_50": df["price"].quantile(q=0.50),
"quantile_75": df["price"].quantile(q=0.75),
"max": df["price"].max(),
}
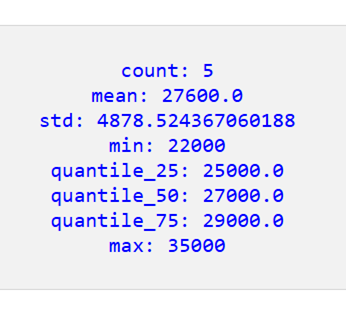
for stat, value in statistics.items():
print(f"{stat}: {value}")
Python でコードを実行すると、次の統計情報が得られます。


")

")
