Pandas DataFrame で NaN (null) 値を含む行を削除するには:
df.dropna()
すべての値が NaN である行を削除するには:
df.dropna(how="all")Pandas DataFrame で NaN 値を含む行を削除する手順
ステップ1: NaN値を持つデータフレームを作成する
import pandas as pd
import numpy as np
data = {"col_a": [1, 2, np.nan, 4],
"col_b": [5, np.nan, np.nan, 8],
"col_c": [9, 10, 11, 12]
}
df = pd.DataFrame(data)
print(df)
ご覧のとおり、2 行目と 3 行目には NaN 値が含まれています。

ステップ2: Pandas DataFrameでNaN値を持つ行を削除する
df.dropna() を使用して、DataFrame 内の NaN 値を持つすべての行を削除します。
import pandas as pd
import numpy as np
data = {"col_a": [1, 2, np.nan, 4],
"col_b": [5, np.nan, np.nan, 8],
"col_c": [9, 10, 11, 12]
}
df = pd.DataFrame(data)
df_dropped = df.dropna()
print(df_dropped)
結果には NaN 値のない 2 つの行があります。
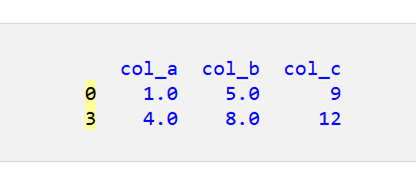
これらの2行の連続インデックスが失われていることに注意してください。現在は0と3です。インデックスを0から始めて連続的に増加するようにリセットできます。
ステップ3(オプション):インデックスをリセットする
Pandas DataFrame でインデックスをリセットするための一般的な構文:
df.reset_index(drop=True)NaN 値を持つ行を削除し、インデックスをリセットする完全なスクリプト:
import pandas as pd
import numpy as np
data = {"col_a": [1, 2, np.nan, 4],
"col_b": [5, np.nan, np.nan, 8],
"col_c": [9, 10, 11, 12]
}
df = pd.DataFrame(data)
df_dropped = df.dropna()
df_reset = df_dropped.reset_index(drop=True)
print(df_reset)
インデックスは 0 から始まり、順番に増加します。

すべての値が NaN である行を削除する
以下は、3 行目のすべての値が NaN である DataFrame の例です。
import pandas as pd
import numpy as np
data = {"col_a": [1, 2, np.nan, 4],
"col_b": [5, np.nan, np.nan, 8],
"col_c": [9, 10, np.nan, 12]
}
df = pd.DataFrame(data)
print(df)
ご覧のとおり、3 行目の値はすべて NaN です。
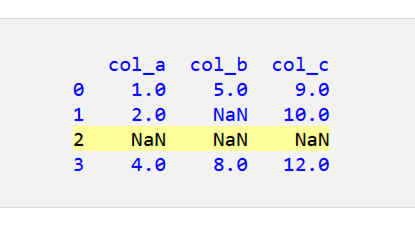
すべての値が NaN である行のみを削除するには、df.dropna(how=”all”) を使用します。
import pandas as pd
import numpy as np
data = {"col_a": [1, 2, np.nan, 4],
"col_b": [5, np.nan, np.nan, 8],
"col_c": [9, 10, np.nan, 12]
}
df = pd.DataFrame(data)
df_dropped = df.dropna(how="all")
print(df_dropped)
結果:






