この短いガイドでは、Pandas を使用して Python でピボット テーブル (pivot table)を作成する方法を説明します。
例
4 四半期にわたる売上に関するデータを含む次の DataFrame があるとします。
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
print(df)
上記のコードを Python で実行すると、次の DataFrame が得られます。
Pandasを使ったPythonのピボットテーブルの5つのシナリオ
シナリオ1: 一人当たり総売上
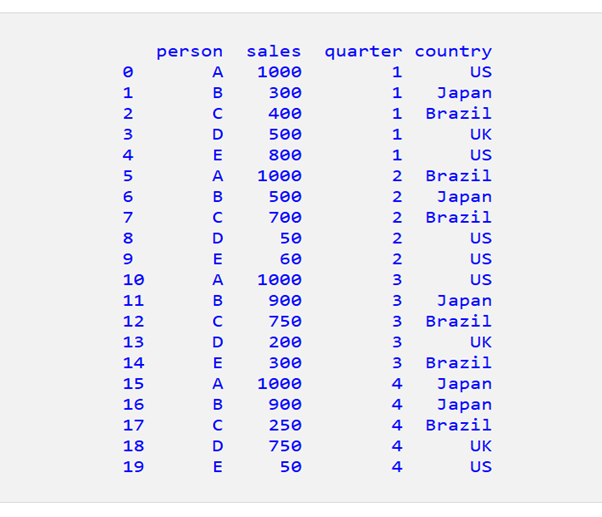
aggfunc=’sum’ を使用して、一人当たりの合計売上(4四半期全体)を取得するには、次のようにします。
pivot = df.pivot_table(index=['person'], values=['sales'], aggfunc='sum')完全なコード:
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
pivot = df.pivot_table(index=['person'], values=['sales'], aggfunc='sum')
print(pivot)
一人当たりの合計売上は以下のとおりです。
シナリオ2: 国別の総売上高
郡ごとに総売上高をグループ化するには(ここでは、「person」フィールドではなく「country」フィールドで結果を集計します):
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
pivot = df.pivot_table(index=['country'], values=['sales'], aggfunc='sum')
print(pivot)
すると、「country」別の総売上高が表示されます。

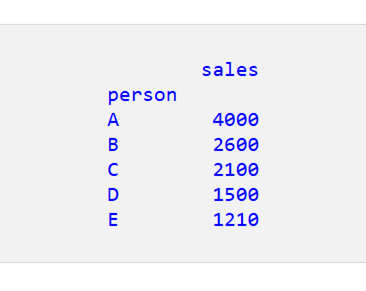
シナリオ3: 個人と国の両方による売上
「person」フィールドや「country」フィールドなど、複数のフィールドで結果を集計することもできます。
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
pivot = df.pivot_table(index=['person', 'country'], values=['sales'], aggfunc='sum')
print(pivot)
コードを実行すると、「person」と「country」の両方の売上が表示されます。
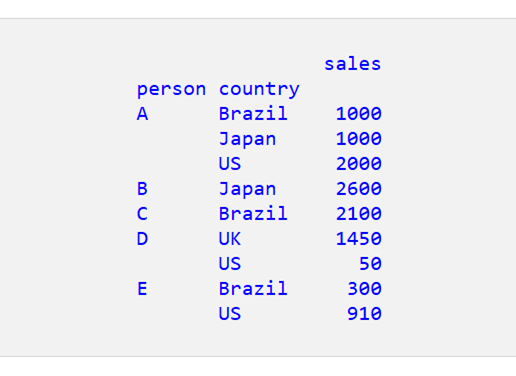
シナリオ4: 国別の最大個別販売
これまで、結果をグループ化するために合計演算 (つまり、aggfunc=’sum’) を使用してきましたが、その演算に限定されるわけではありません。
このシナリオでは、aggfunc=’max’ を使用して郡別の最大個別売上を見つけます。
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
pivot = df.pivot_table(index=['country'], values=['sales'], aggfunc='max')
print(pivot)
そして結果は次の通りです。

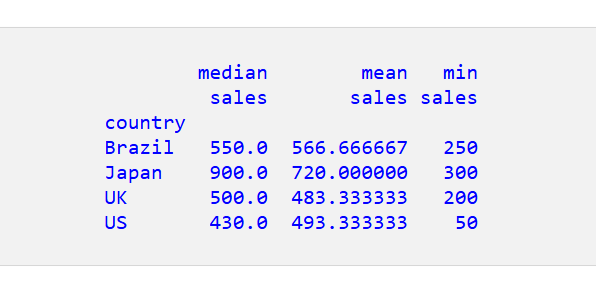
シナリオ5: 国別の売上高の中央値、平均値、最小値
aggfunc 引数では複数の演算を使用できます。例えば、国別の売上高の中央値、平均値、最小値を求めるには、次のようにします。
aggfunc=['median', 'mean', 'min']
完全な Python コードは次のとおりです。
import pandas as pd
data = {'person': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'sales': [1000, 300, 400, 500, 800, 1000, 500, 700, 50, 60, 1000, 900, 750, 200, 300, 1000, 900, 250, 750, 50],
'quarter': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4],
'country': ['US', 'Japan', 'Brazil', 'UK', 'US', 'Brazil', 'Japan', 'Brazil', 'US', 'US', 'US', 'Japan',
'Brazil', 'UK', 'Brazil', 'Japan', 'Japan', 'Brazil', 'UK', 'US']
}
df = pd.DataFrame(data)
pivot = df.pivot_table(index=['country'], values=['sales'], aggfunc='max')
print(pivot)
すると、次の結果が得られます。
5つのシンプルなシナリオでピボットテーブルを作成する方法をご覧いただきました。しかし、ここで紹介した概念は、さまざまなシナリオに適用できます。





