このセクションでは、PostgreSQL テーブルで重複行を検索する方法について説明します。PostgreSQL テーブルで重複行を検索するには、GROUP BY 句と HAVING 句を併用します。PostgreSQL テーブルで重複行を検索するには、複数の方法を使用できます。それぞれの方法については例を挙げて説明します。
- PostgreSQL の単一列に重複する値を持つ行を見つける
- PostgreSQL で複数の列に重複した値を持つ行を見つける
- PostgreSQL のテーブル全体の重複行を見つける
- PostgreSQLで重複行をすべて表示する
描写に使用した表は
examscore_dup:
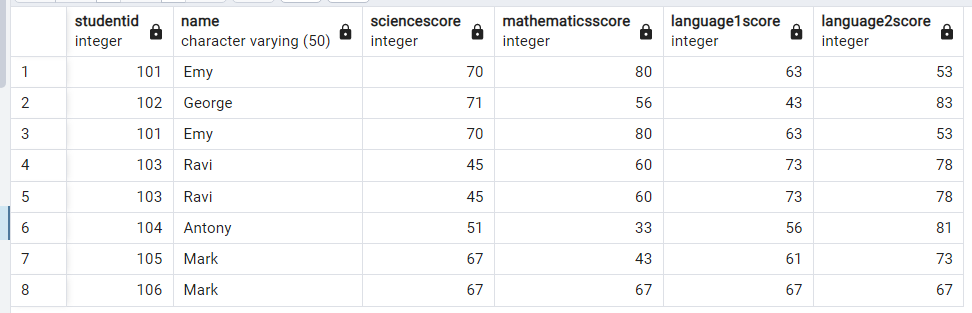
PostgreSQL テーブル内の重複行を検索します。
方法1: group byを使用して
select distinct * from examscore_dup where studentid in ( select studentid from (
select studentid, count(*)
from examscore_dup
group by studentid
HAVING count(*) > 1) as foo);
各 STUDENTID の行数を数えて重複行を選択し、count > 1 の行を選択しました。
出力:

方法2: PostgreSQLでパーティション分割を使用して重複行を検索する
以下に示すように、パーティションと順序によって重複行を選択しました。
select distinct * from examscore_dup where studentid in (
select studentid from (
select studentid,
ROW_NUMBER() OVER(PARTITION BY studentid ORDER BY studentid asc) AS Row
FROM examscore_dup
) as foo
where
foo.Row > 1);出力:

重複行をすべて表示:
重複を排除せずにすべての重複行を表示するには、以下のコードを使用します。
SELECT *
FROM examscore_dup
WHERE (studentid, name) IN (
SELECT studentid, name
FROM examscore_dup
GROUP BY name, studentid
HAVING COUNT(*) > 1
);上記のクエリは、すべての重複行をこのように生成します。重複が3回出現する場合は、3行すべてが表示されます。
出力:

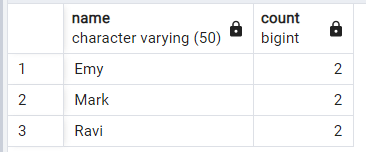
PostgreSQL の単一列内の重複行を検索します。
名前などの単一の列に基づいて重複行を検索するには、次のクエリを使用します。
SELECT name, COUNT(*)
FROM examscore_dup
GROUP BY name
HAVING COUNT(*) > 1;このクエリは、名前列ごとに行をグループ化し、それぞれの名前の出現回数をカウントします。HAVING COUNT(*) > 1 句は結果をフィルタリングし、複数回出現する名前のみを表示します。
出力:
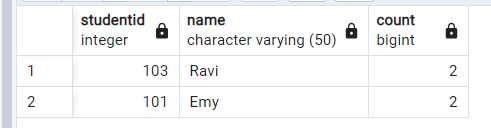
PostgreSQL で複数の列に基づいて重複を見つける:
「name」や「studentid」など、複数の列に基づいて重複行を検索するには、同様の方法を使用できます。
SELECT studentid,name, COUNT(*)
FROM examscore_dup
GROUP BY studentid,name
HAVING COUNT(*) > 1;このクエリは、name 列と studentid 列の両方で行をグループ化し、それぞれの組み合わせの出現回数をカウントします。HAVING COUNT(*) > 1 句は結果をフィルタリングし、複数回出現する組み合わせのみを表示します。
出力:




 関数")
