このセクションでは、PostgreSQL で重複行を削除する方法について説明します。PostgreSQL テーブルで重複行を削除するには、distinct キーワードや Partition by などの複数の方法を使用できます。これらの方法では、テーブルの重複行のみが保持されます。これらの各方法については、例を挙げて説明します。
- PostgreSQL テーブル内の一意の行のみを保持する
- PostgreSQLテーブル内の不要な重複行を削除する
- 重複する ID を持つ行を削除し、重複する ID を持たない行のみを保持します。
描写に使用した表は
examscore:
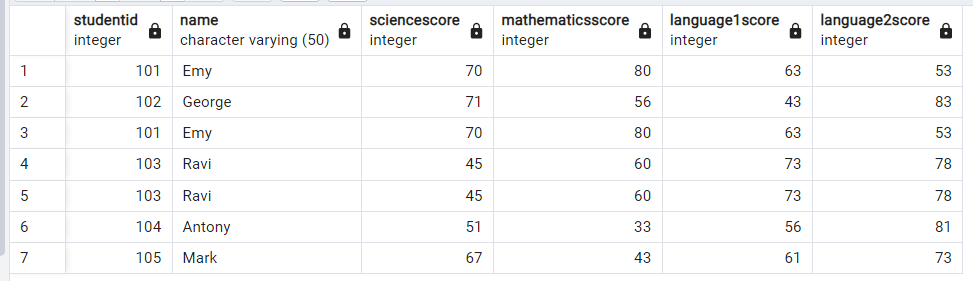
PostgreSQL で重複行を削除する: 方法 1 (PostgreSQL で重複行または一意の行を選択する)
不要な重複を排除してデータを選択する最も効率的で最速の方法です
select distinct * from ExamScore出力:
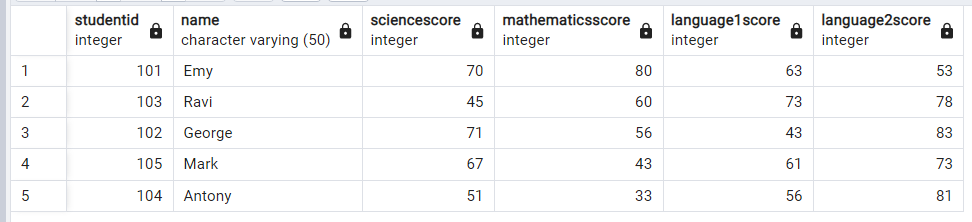
方法2: 不要な重複を削除し、一意の行のみを返す
select distinct * from examscore where studentid in (
select studentid from (
select studentid,
ROW_NUMBER() OVER(PARTITION BY studentid ORDER BY studentid asc) AS Row
FROM examscore
) as foo
where
foo.Row = 1);- PARTITION BY はグループに分割し、ORDER BY は降順で並べ替えます。
- ROW_NUMBER() は、各カテゴリのすべての行に整数を割り当てます。
- 行番号が1より大きい重複行はwhere条件で削除され、PostgreSQLでは一意の行のみを含むテーブルが作成されます。
出力:
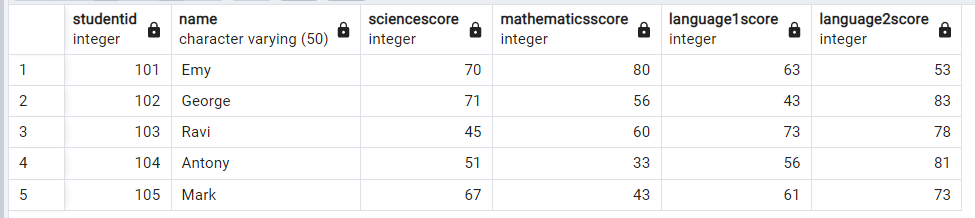
方法3: 重複しているIDを削除する
重複する ID を削除するには、つまり重複する ID を持つ行を削除し、重複する ID を持たない行のみを保持します。
SELECT *
FROM examscore
WHERE (studentid) IN (
SELECT studentid
FROM examscore
GROUP BY name, studentid
HAVING COUNT(*) = 1
);STUDENTID列では重複するIDを削除し、重複しないIDのみを保持する必要があります。そして、重複しないIDの行を保持する必要があります。これは上記のコードで実現できます。
STUDENTID 101と103は複数回出現するため削除されます。
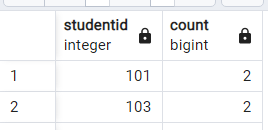
結果のテーブルには重複しないIDがすべて含まれることになります
出力:


, LAST_VALUE(), Nth_VALUE()")
 および LAG() 関数")

