RegEx を使用して Pandas DataFrame の行をフィルターするさまざまな方法を次に示します。
(1)名前が「B」で始まる行をすべて取得します。
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
pattern = r'^B\w*'
df_filtered = df[df['name'].str.contains(pattern)]
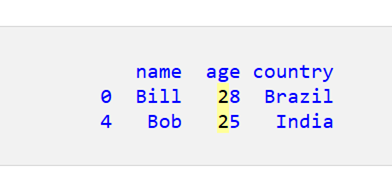
print(df_filtered)
名前が「B」で始まる行のみが取得されます。
^B\w*のパターンの場合
- ^文字列の始まりを表す
- B「B」の文字を表す
- \w*0文字以上の文字を表す
(2)名前が「l」で終わる行をすべて取得する。
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
pattern = r'\w*l$'
df_filtered = df[df['name'].str.contains(pattern)]
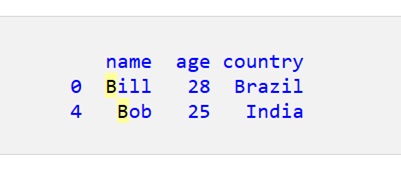
print(df_filtered)
名前が ‘l’ で終わる行のみが取得されます。
\w*l$のパターンの場合
- \w*0文字以上の文字を表す
- l「l」の文字を表す
- $文字列の終わりを示す
(3)名前が「B」で始まるか国名が「C」で始まる行をすべて取得します。
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
pattern_name = r'^B\w*'
pattern_city = r'^C\w*'
df_filtered = df[df['name'].str.contains(pattern_name) | df['country'].str.contains(pattern_city)]
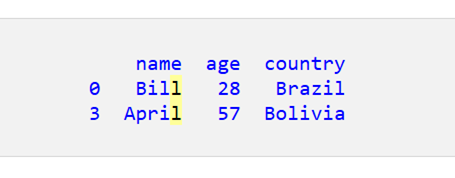
print(df_filtered)
ここでは、名前が「B」で始まるか、国が「C」で始まります。
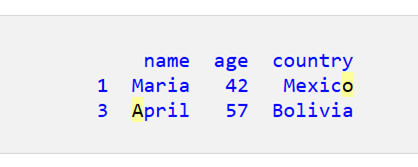
(4) 名前が「A」で始まるか国名が「o」で終わる行をすべて取得します。
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
pattern_name = r'^A\w*'
pattern_city = r'\w*o$'
df_filtered = df[df['name'].str.contains(pattern_name) | df['country'].str.contains(pattern_city)]
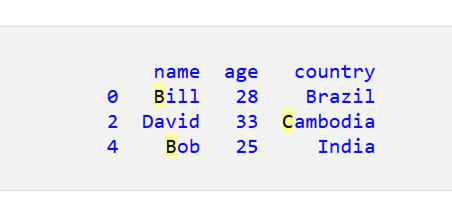
print(df_filtered)
現在、名前は「A」で始まり、国名は「o」で終わります。
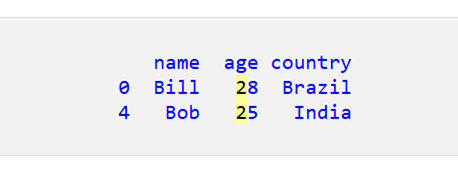
(5) 年齢が「2」で始まる行をすべて取得します。
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
pattern = r'^2'
df_filtered = df[df['age'].astype(str).str.contains(pattern)]
print(df_filtered)
年齢が「2」で始まる行のみが取得されます。
または:
import pandas as pd
data = {'name': ['Bill', 'Maria', 'David', 'April', 'Bob'],
'age': [28, 42, 33, 57, 25],
'country': ['Brazil', 'Mexico', 'Cambodia', 'Bolivia', 'India']
}
df = pd.DataFrame(data)
df_filtered = df[df['age'].astype(str).str.startswith('2')]
print(df_filtered)
結果: